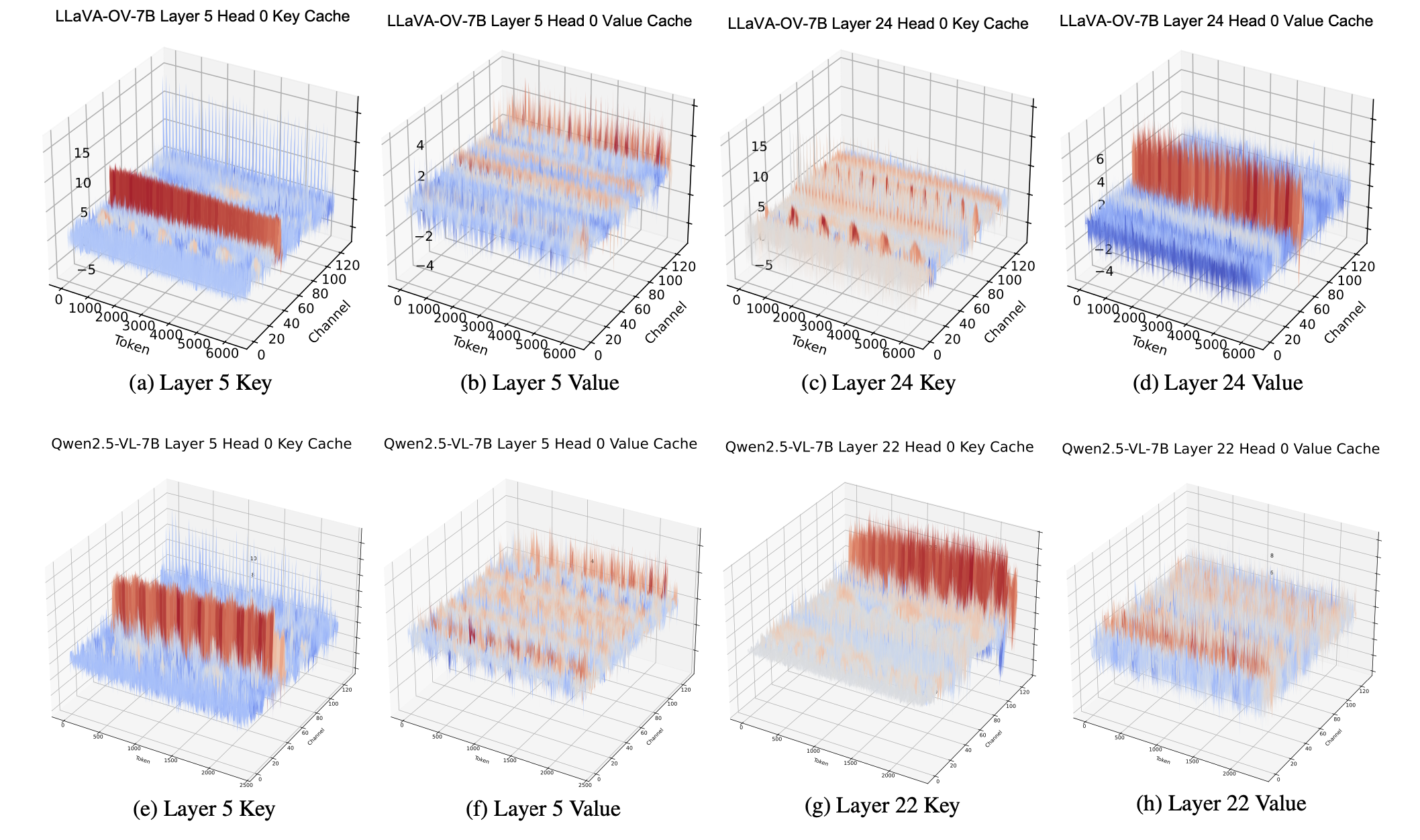
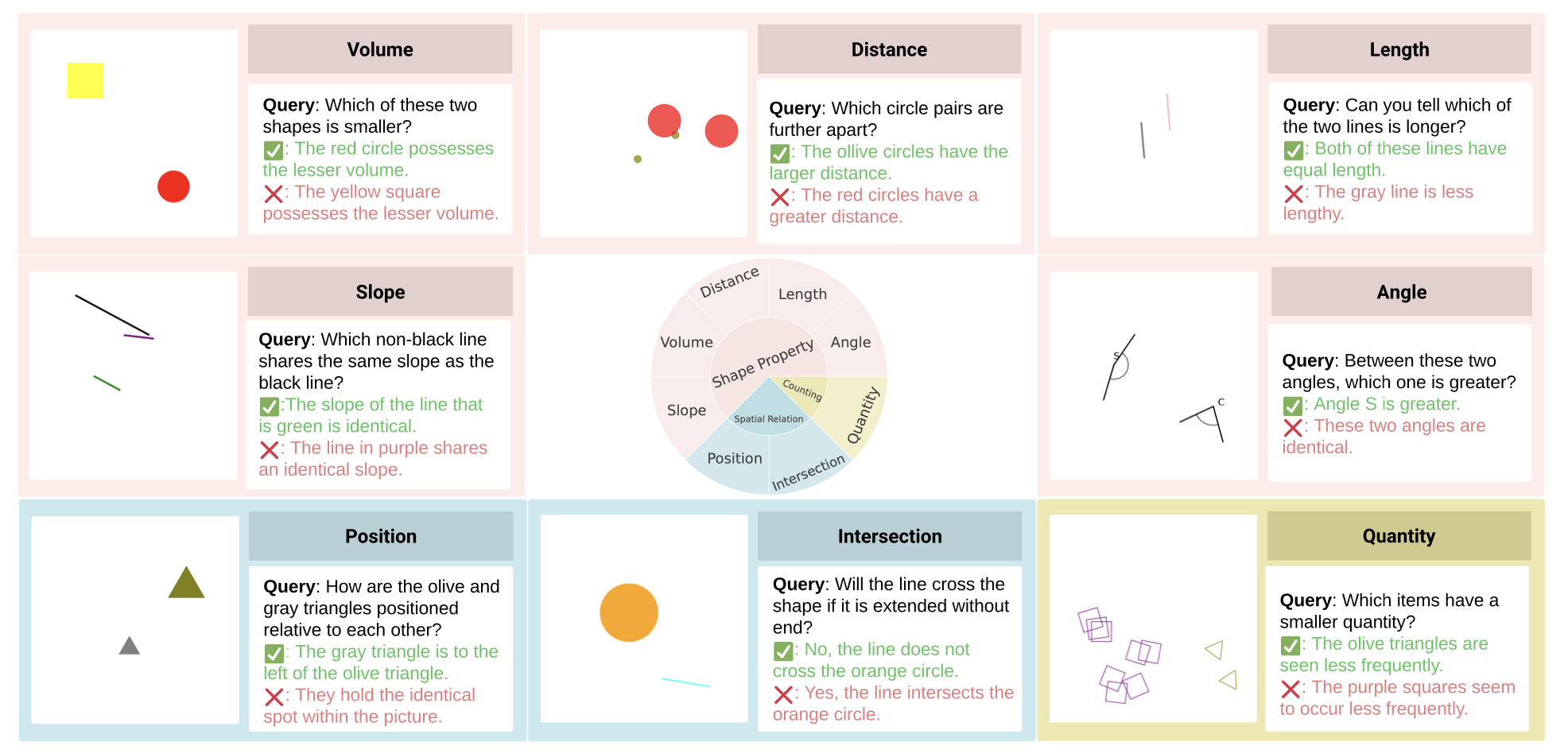
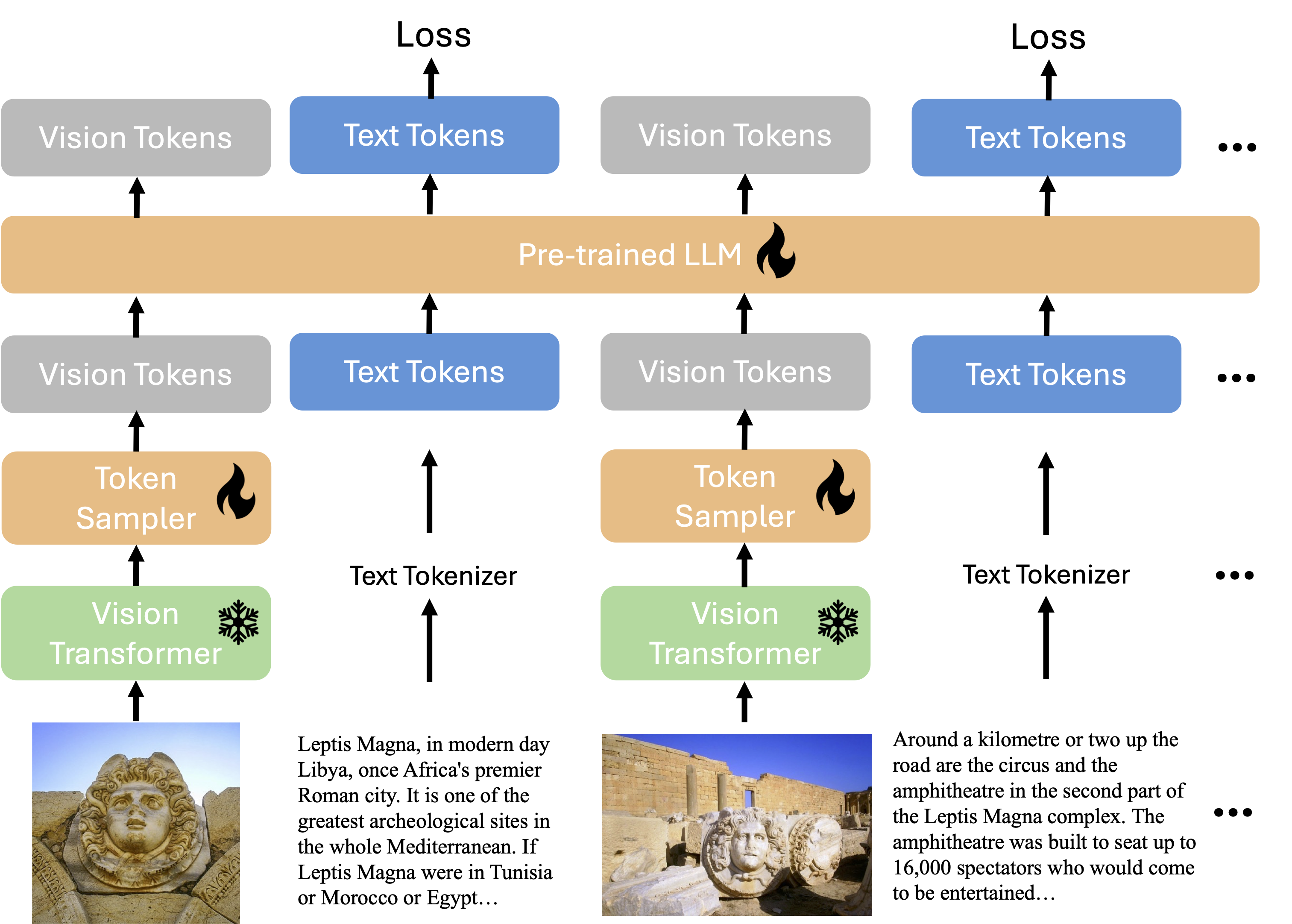
Can Qin
Salesforce AI Research, 181 Lytton Avenue, Palo Alto, CA, 94301, USA

Email: cqin[at]salesforce.com or qin.ca[at]northeastern.edu
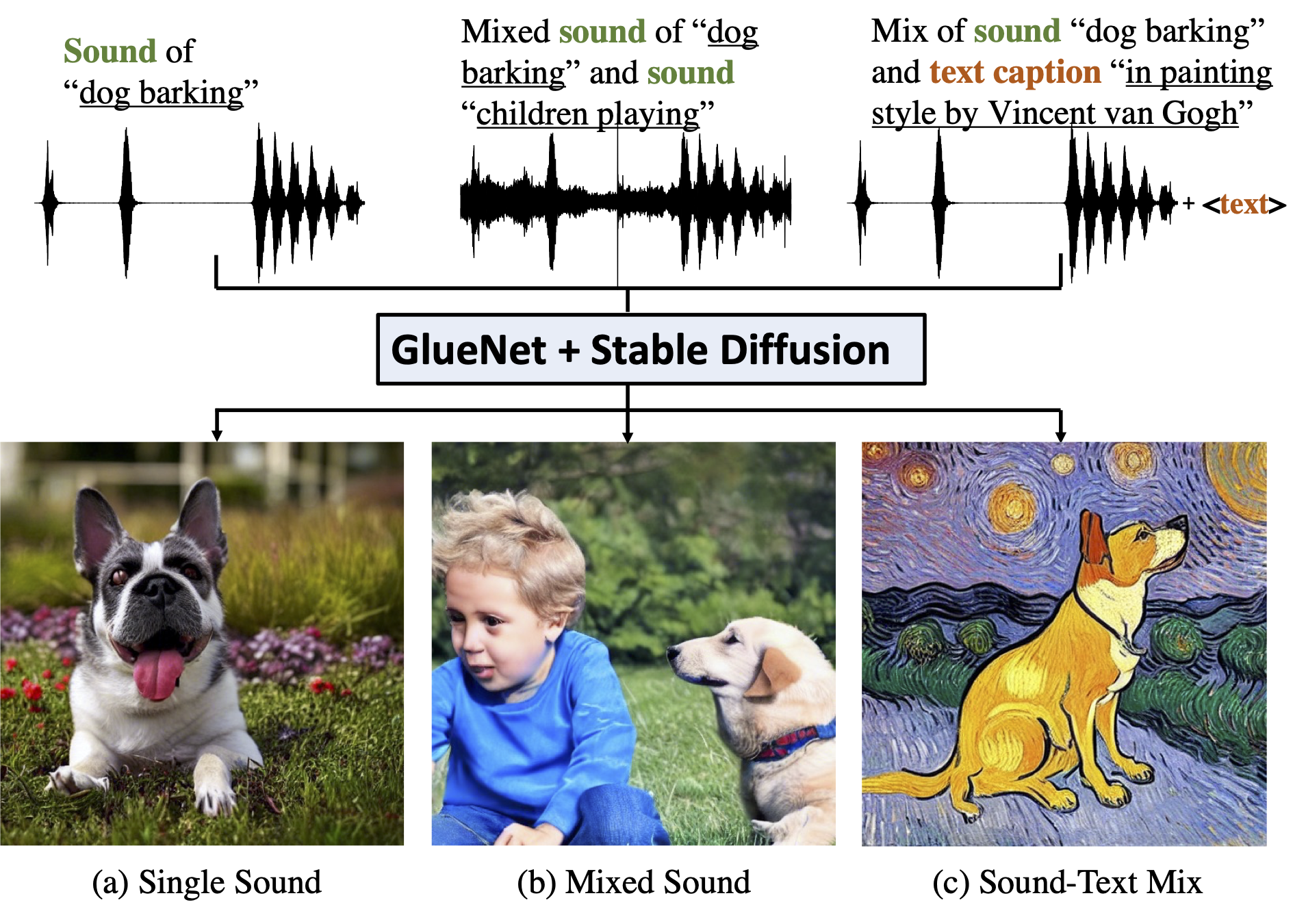
Hello and welcome! I’m currently embracing the exciting world of artificial intelligence as a Research Scientist at Salesforce AI Research. My journey is driven by a deep passion for Generative AI and Multi-modal Learning, with a focus on developing Video/Image to Text (Understanding) and Text to Video/Image (Generation) techniques.
In 2023, I earned my Ph.D. from Northeastern University in Boston, USA. My research during this period was primarily centered around the realms of Transfer Learning and Efficient AI, where I delved into complex problems and innovative solutions.
Before my Ph.D. journey, I obtained my B.E. degree from Xidian University in Xi’an, China, in 2018. This foundation laid the groundwork for my ongoing pursuit of knowledge and innovation.
news
| Oct, 2025 | Holitom was accepted by NeurIPS 25. We have released the CoDA (a 1.7b coding DLLM model). |
|---|---|
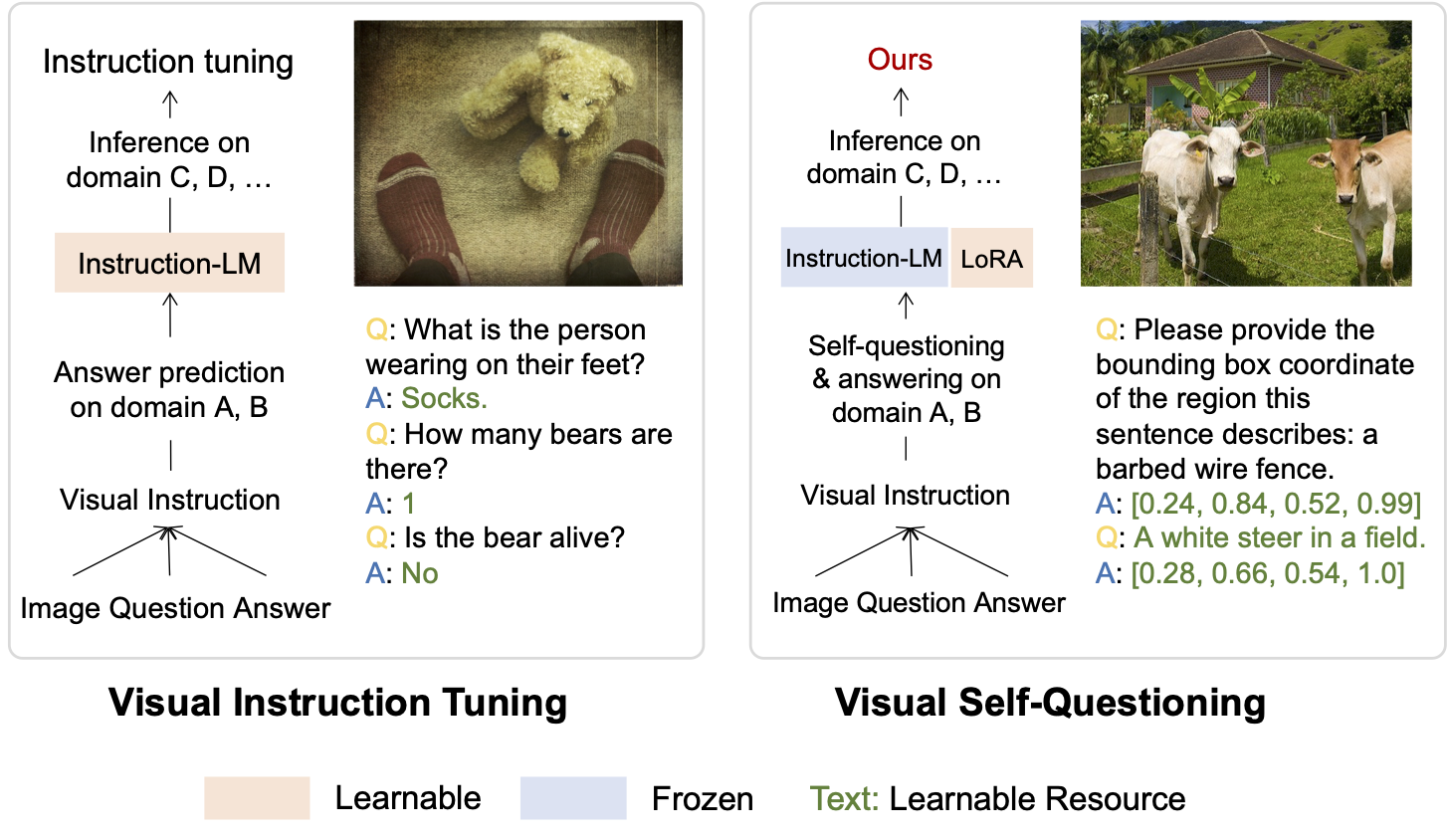
| May, 2025 | CogAlign was accepted by ACL findings and we have released BLIP-3o. |
| Feb, 2025 | We have two papers accepted by CVPR 25! Our latest paper CogAlign was released. |
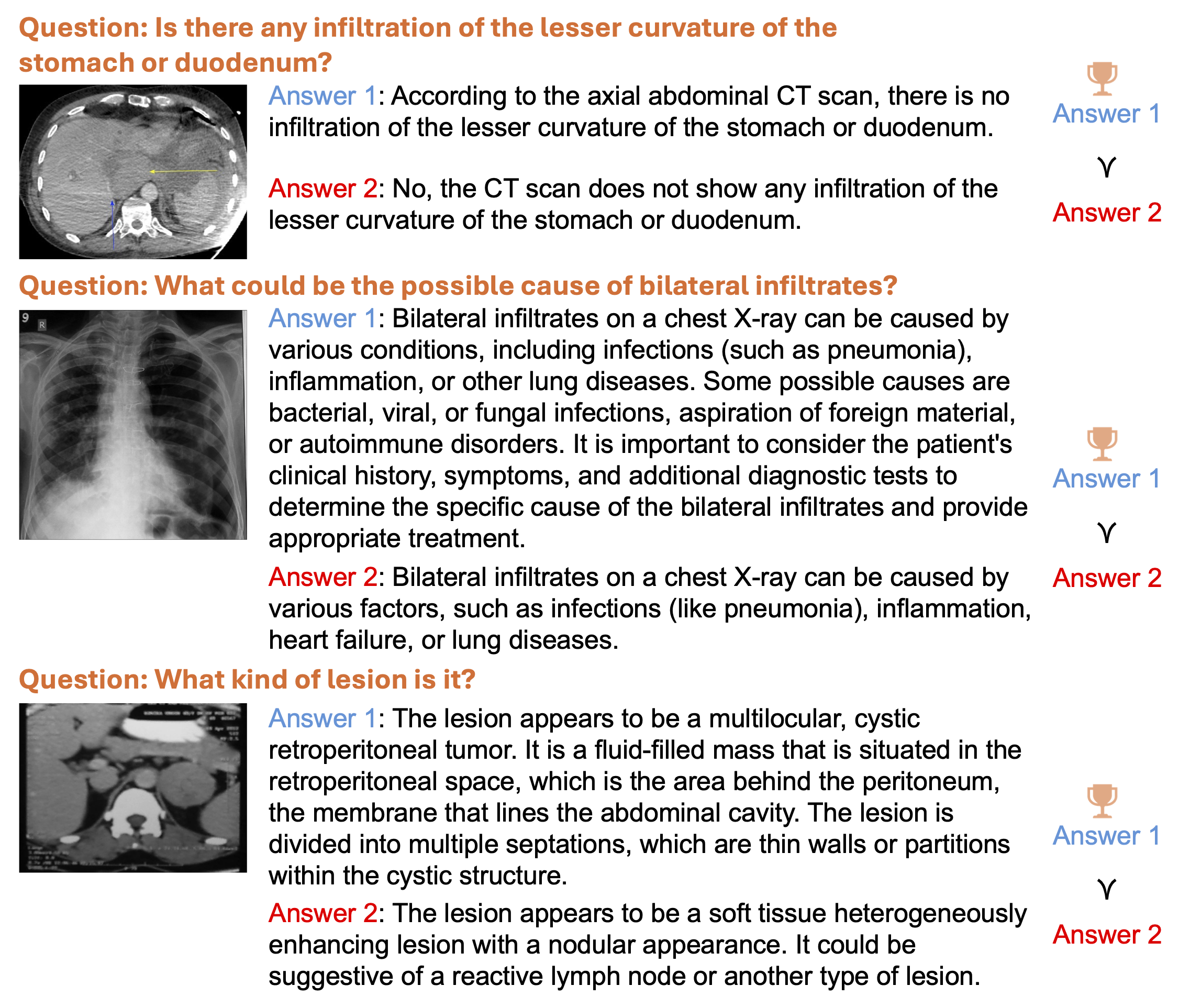
| Sep, 2024 | Our Medical MLLM paper was accepted by EMNLP 24 (Main)! |
| Aug, 2024 | The xGen-MM (BLIP3) and xGen-VideoSyn-1 were released to the public! We have a paper accepted by TKDE and congrats to Yizhou! I have been invited as the reviewer of Nature Communications. |
| Jul, 2024 | We have one paper accepted by ECCV 24! |
| Feb, 2024 | We have one paper accepted by CVPR 24! |
| Nov, 2023 | Begin my journey at Salesforce Research in Palo Alto! |
| Jun, 2023 | I have passed the PhD Dissertation Defense and become Dr. Qin! |